17. Analysis plugin development¶
Users can write their own plugins for performing the collocation of two data sets. There are three different types of plugin available for collocation, first we will describe the overall design and how these different components interact, then each will be described in more detail.
17.1. Basic collocation design¶
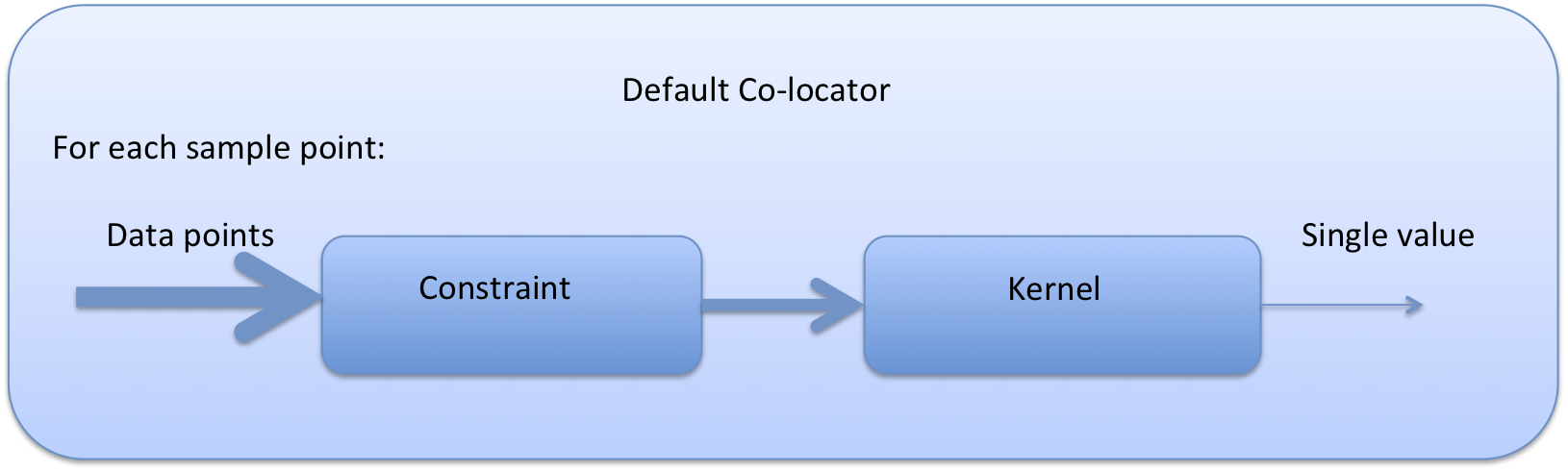
The diagram below demonstrates the basic design of the collocation system, and the roles of each of the components. In the simple case of the default collocator (which returns only one value) the Collocator loops over each of the sample points, calls the relevant Constraint to reduce the number of data points, and then the Kernel which returns a single value, which the collocator stores.
17.2. Kernel¶
A kernel is used to convert the constrained points into values in the output. There are two sorts of kernel one
which act on the final point location and a set of data points (these derive from Kernel) and the more specific kernels
which act upon just an array of data (these derive from AbstractDataOnlyKernel, which in turn derives from Kernel).
The data only kernels are less flexible but should execute faster. To create a new kernel inherit from Kernel and
implement the abstract method Kernel.get_value(). To make a data only kernel inherit from AbstractDataOnlyKernel
and implement AbstractDataOnlyKernel.get_value_for_data_only() and optionally overload AbstractDataOnlyKernel.get_value().
These methods are outlined below.
-
Kernel.get_value(point, data) This method should return a single value (if
Kernel.return_sizeis 1) or a list of n values (ifKernel.return_sizeis n) based on some calculation on the data given a single point.The data is deliberately left unspecified in the interface as it may be any type of data, however it is expected that each implementation will only work with a specific type of data (gridded, ungridded etc.) Note that this method will be called for every sample point and so could become a bottleneck for calculations, it is advisable to make it as quick as is practical. If this method is unable to provide a value (for example if no data points were given) a ValueError should be thrown.
Parameters: - point – A single HyperPoint
- data – A set of data points to reduce to a single value
Returns: For return_size=1 a single value (number) otherwise a list of return values, which represents some operation on the points provided
Raises: ValueError – When the method is unable to return a value
-
AbstractDataOnlyKernel.get_value_for_data_only(values) This method should return a single value (if
Kernel.return_sizeis 1) or a list of n values (ifKernel.return_sizeis n) based on some calculation on the the values (a numpy array).Note that this method will be called for every sample point in which data can be placed and so could become a bottleneck for calculations, it is advisable to make it as quick as is practical. If this method is unable to provide a value (for example if no data points were given) a ValueError should be thrown. This method will not be called if there are no values to be used for calculations.
Parameters: values – A numpy array of values (can not be none or empty) Returns: A single data item if return_size is 1 or a list of items containing Kernel.return_sizeitemsRaises: ValueError – If there are any problems creating a value
17.3. Constraint¶
The constraint limits the data points for a given sample point.
The user can also add a new constraint mechanism by subclassing Constraint and providing an implementation for
Constraint.constrain_points(). If more control is needed over the iteration sequence then the
Constraint.get_iterator() method can also be
overloaded. Note however that this may not be respected by all collocators, who may still iterate over all
sample data points. It is possible to write your own collocator (or extend an existing one) to ensure the correct
iterator is used - see the next section. Both these methods, and their signatures, are outlined below.
-
Constraint.constrain_points(point, data) This method should return a subset of the data given a single reference point. It is expected that the data returned should be of the same type as that given - but this isn’t mandatory. It is possible that this function will return zero points (no data), the collocation class is responsible for providing a fill_value.
Parameters: - point (HyperPoint) – A single HyperPoint
- data – A set of data points to be reduced
Returns: A reduced set of data points
-
Constraint.get_iterator(missing_data_for_missing_sample, coord_map, coords, data_points, shape, points, output_data) Iterator to iterate through the points needed to be calculated. The default iterator, iterates through all the sample points calling
Constraint.constrain_points()for each one.Parameters: - missing_data_for_missing_sample – If true anywhere there is missing data on the sample then final point is missing; otherwise just use the sample
- coord_map – Coordinate map - list of tuples of indexes of hyperpoint coord, data coords and output coords
- coords – The coordinates to map the data onto
- data_points – The (non-masked) data points
- shape – Shape of the final data values
- points – The original points object, these are the points to collocate
- output_data – Output data set
Returns: Iterator which iterates through (sample indices, hyper point and constrained points) to be placed in these points
To enable a constraint to use a AbstractDataOnlyKernel, the method
get_iterator_for_data_only() should be implemented (again though, this may be ignored by a collocator). An
example of this is the BinnedCubeCellOnlyConstraint.get_iterator_for_data_only() implementation.
17.4. Collocator¶
Another plugin which is available is the collocation method itself. A new one can be created by subclassing Collocator and
providing an implementation for Collocator.collocate(). This method takes a number of sample
points and applies the given constraint and kernel methods on the data for each of those points. It is responsible for
returning the new data object to be written to the output file. As such, the user could create a collocation routine
capable of handling multiple return values from the kernel, and hence creating multiple data objects, by creating a
new collocation method.
Note
The collocator is also responsible for dealing with any missing values in sample points. (Some sets of sample points may
include values which may or may not be masked.) Sometimes the user may wish to mask the output for such points, the
missing_data_for_missing_sample attribute is used to determine the expected behaviour.
The interface is detailed here:
-
Collocator.collocate(points, data, constraint, kernel) The method is responsible for setting up and running the collocation. It should take a set of data and map that onto the given (sample) points using the constraint and kernel provided.
Parameters: - points – A set of sample points onto which we will collocate some other ‘data’
- data – Some other data to be collocated onto the ‘points’
- constraint – A
Constraintinstance which provides aConstraint.constrain_points()method, and optionally anConstraint.get_iterator()method - kernel – A
Kernelinstance which provides aKernel.get_value()method
Returns: One or more
CommonData(or subclasses of) objects whose coordinates lie on the points defined above.
17.5. Implementation¶
For all of these plugins any new variables, such as limits, constraint values or averaging parameters,
are automatically set as attributes in the relevant object. For example, if the user wanted to write a new
constraint method (AreaConstraint, say) which needed a variable called area, this can be accessed with self.area
within the constraint object. This will be set to whatever the user specifies at the command line for that variable, e.g.:
$ ./cis.py col my_sample_file rain:"model_data_?.nc"::AreaConstraint,area=6000,fill_value=0.0:nn_gridded
Example implementations of new collocation plugins are demonstrated below for each of the plugin types:
class MyCollocator(Collocator):
def collocate(self, points, data, constraint, kernel):
values = []
for point in points:
con_points = constraint.constrain_points(point, data)
try:
values.append(kernel.get_value(point, con_points))
except ValueError:
values.append(constraint.fill_value)
new_data = LazyData(values, data.metadata)
new_data.missing_value = constraint.fill_value
return new_data
class MyConstraint(Constraint):
def constrain_points(self, ref_point, data):
con_points = []
for point in data:
if point.value > self.val_check:
con_points.append(point)
return con_points
class MyKernel(Kernel):
def get_value(self, point, data):
nearest_point = point.furthest_point_from()
for data_point in data:
if point.compdist(nearest_point, data_point):
nearest_point = data_point
return nearest_point.val